假设一张表具有多个相似简单Char字段用来存储Excel表格中的测量结果,默认创建的Char字段数量为10,那么如果测量结果只有10个,则刚好足够存储,但如果测量结果达到了15个 ,那么多出的5个结果无法存储。有两种方法可以处理这种情况:
- 将Char字段更改为One2many字段
- 动态添加Char字段
使用第一种方法的优点是十分简单,更改字段类型即可;但缺点也十分明显,那就是需要多创建一个模型,而且模型里面只有一个字段,这样在视图中的展现也不太美观。因此,这里我们使用第二种方法‘动态添加字段’。动态添加的方式除了更贴近表格之外,也更符合我们习惯的操作。
首先,分析动态添加字段需要面临的几个问题
- 如何动态添加字段
- 如何动态更新视图模型
- 如何获取到动态添加的字段
简单的思路是使用create方法新增字段,用一个模型保存新增的字段,使用xpath将字段插入视图当中。
代码实现参考现有的代码,代码是参考徐春老师的代码写出来的,因此先分析徐老师的代码,下面贴出源码:
# -*- coding: utf-8 -*-
import re
import random
from odoo import models, fields, api, _
from pypinyin import lazy_pinyin, Style
class PartnerGroup(models.Model):
_inherit = 'partner.group'
field_id = fields.Many2one('ir.model.fields', string='关联字段', readonly=True)
view_id = fields.Many2one('ir.ui.view', string='关联视图', readonly=True)
@api.model_create_multi
def create(self, vals_list):
model = self.env['ir.model'].search([('model', '=', 'stock.price.adjustment.line')], limit=1)
tree_view_ref = self.env.ref('stock_price_adjustment.view_stock_price_adjustment_line_tree', False)
for vals in vals_list:
# 使用正则将所有非字母数字字符都转换为下划线 _
converted_name = re.sub(r'\W+', '_', vals.get('name'))
# 创建字段
field_name = f"x_{''.join(lazy_pinyin(converted_name, style=Style.FIRST_LETTER))}_{random.randint(0,10000)}" # 字段的名字为 x_ + 拼音 + 随机数
field = self.env['ir.model.fields'].create([{
'model_id': model.id,
'name': field_name,
'field_description': vals.get('name'), # 字段的名称为客户组的名称,也用于搜索此字段,故此名称应唯一
'ttype': 'float',
}])
vals['field_id'] = field.id
# 创建视图
view = self.env["ir.ui.view"].create({
"name": f"存库调价价格表新增 {vals.get('name')} 字段",
"model": "stock.price.adjustment.line",
"type": "tree",
"inherit_id": tree_view_ref.id,
"arch": f"""<xpath expr="//field[@name='sale_secondary_uom']" position="after">
<field name="{field_name}"/>
</xpath>"""
})
vals['view_id'] = view.id
return super().create(vals_list)
def unlink(self):
""" 删除时将生成的视图归档掉 """
for rec in self:
rec.view_id.action_archive()
return super(PartnerGroup, self).unlink(
需要了解的是,odoo是基于模块/模型的编码,对对象的增删改查通常可以通过模型的增删改查来执行,模型的名称保存在env当中的,因此可以通过env[model_name]获取到对应的模型。
在代码中,创建了两个变量field_id和view_id,先说明它们的意义,它们是分别用于关联我们等一下新增的字段和视图模型的。你可能会问,诶,关联字段可以理解,视图为什么也要关联呢,这需要了解odoo当中视图的实现了。
odoo中视图同样作为模型需要存储在数据库当中,作为模型,他的一大特点就是可以继承其他的模型,因此odoo中,可以经常见到一个视图继承其他父视图。也就是说我们新增一个字段可以创建一个新的视图用来继承原来的视图,这样说是不是就理解为什么创建一个关联视图的字段了呢?下面通过图形来方便我们的理解:
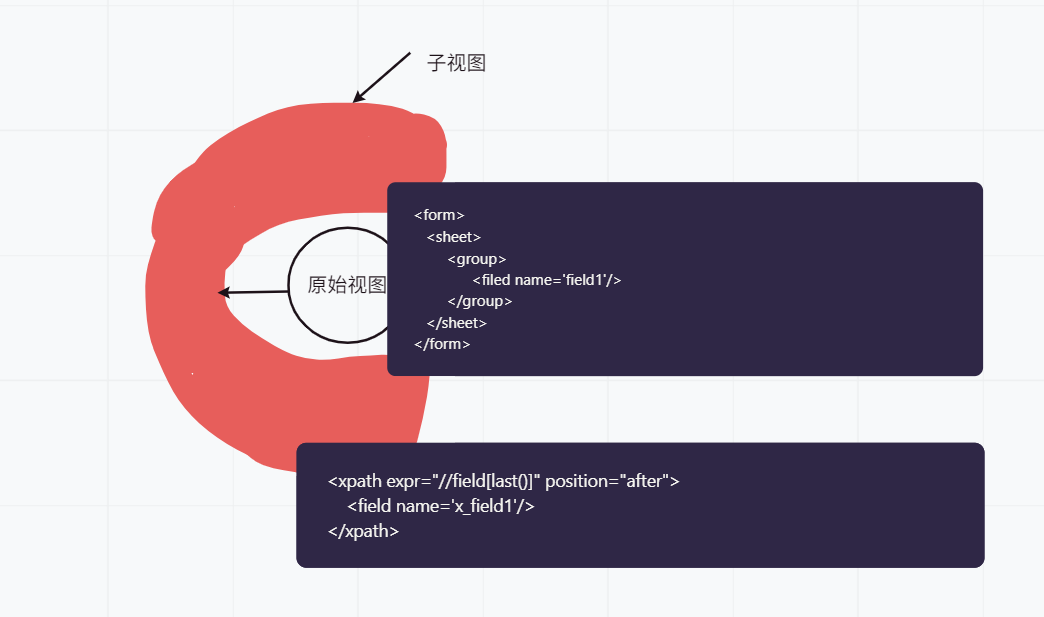
图中的x_field1就是新增的字段。
在代码中,通过create方法创建一个新的字段
field = self.env['ir.model.fields'].create([{
'model_id': model.id,
'name': field_name,
'field_description': vals.get('name'), # 字段的名称为客户组的名称,也用于搜索此字段,故此名称应唯一
'ttype': 'float',
}])
其中model_id表示的是字段所在的模型的id,代码中的模型是stock.price.adjustment.line;name表示的是字段的名称,field_description是字段的描述,相当于string;ttype表示字段的类型。
紧接着又创建了一个新的视图
view = self.env["ir.ui.view"].create({
"name": f"存库调价价格表新增 {vals.get('name')} 字段",
"model": "stock.price.adjustment.line",
"type": "tree",
"inherit_id": tree_view_ref.id,
"arch": f"""<xpath expr="//field[@name='sale_secondary_uom']" position="after">
<field name="{field_name}"/>
</xpath>"""
})
其中,name表示视图的名称,model表示关联的模型,type表示视图的类型,inherit_id表示继承的视图,代码中继承的是自定义的stock_price_adjustment.view_stock_price_adjustment_line_tree视图;最后,也是相当重要的一部分,是新增字段在视图中展示的位置,这一步直接更改了视图,使得字段得以呈现。到这里,代码中最终要的部分也就分析完毕了。
最后的最后,附上我参考后写的一段代码:
class FailureRatePoint(models.Model):
_name = 'tx.failure.rate.point'
_description = 'Failure Rate By Point'
summary_id = fields.Many2one('tx.rep.review.gap.yield.summary', string='Summary', required=True)
field_id = fields.Many2one('ir.model.fields', string='Related Field', readonly=True)
view_id = fields.Many2one('ir.ui.view', string='Related View', readonly=True)
counter = fields.Integer('Counter', default=2, store=True) # 计数器
@api.onchange('counter')
def _onchange_save(self):
self.write({
'counter': self.counter
})
@api.model_create_multi
def create(self, vals_list):
# 获取最大值
counter = self.env['tx.failure.rate.point'].search([], order='counter desc', limit=1).counter + 1
_name = f'{chr(120)}_'
field_name = f'{_name}{counter}'
desc_name = f'{_name}{counter}'.upper()
model = self.env['ir.model'].search([('model', '=', 'tx.gap.yield.summary.line')], limit=1)
tree_view_ref = self.env.ref('plm_project_quality.tx_gap_yield_summary_line_tree', False)
for vals in vals_list:
# Create field
field = self.env['ir.model.fields'].create([{
'model_id': model.id,
'name': field_name,
'field_description': desc_name,
'ttype': 'float',
}])
vals['field_id'] = field.id
# Create view
view = self.env["ir.ui.view"].create({
"name": f"Add {field_name} Field",
"model": "tx.gap.yield.summary.line",
"type": "tree",
"inherit_id": tree_view_ref.id,
"arch": f"""<xpath expr="//field[last()]" position="after">
<field name="{field_name}" optional="show"/>
</xpath>"""
})
vals['view_id'] = view.id
vals['counter'] = counter
return super().create(vals_list)
def unlink(self):
for rec in self:
rec.view_id.unlink()
rec.field_id.unlink()
return super(FailureRatePoint, self).unlink()
模型中增加方法
def add_failure_point(self):
for rec in self:
point_id = self.env['tx.failure.rate.point'].create({
'summary_id': rec.id,
})
# 刷新页面
return {
'type': 'ir.actions.client',
'tag': 'reload',
}
需要关注的部分是:
类名、_name: 更改为你新增字段的名称,注意:FailureRatePoint类只是起到一个链接作用用于模型和新增字段的操作。
summary_id: 关联的是需要新增字段的模型
model: 字段插入的模型
tree_view_ref: 继承的tree视图
只要更改这些部分,就可以直接使用了,新增的字段为x_1、x_2、x_3、...!
模型动态添加字段